Коротко о главном:
-
Суть: кластеризация — это объединение поисковых запросов в группы по смыслу и пересечению выдачи, чтобы одна страница работала на один интент.
-
Цель: защитить сайт от каннибализации, когда две страницы конкурируют за один ключ и теряют позиции.
-
Методы: логическая (ручная), автоматическая (по SERP) и машинная (AI/Python). Жёсткость настройки — hard, middle, soft — зависит от ниши.
-
Вывод для бизнеса: 1 кластер = 1 посадочная страница. Правильная группировка экономит бюджет и ускоряет рост позиций.
Распределение ключевых слов по страницам — это та задача, на которой решается, будет ли SEO-стратегия приносить заявки или превратится в борьбу страниц одного сайта между собой. Когда два-три URL пытаются ранжироваться по одному запросу, поисковая система просто не понимает, какую страницу показывать пользователю. Итог печальный. В выдаче проседают обе: вместо одной сильной позиции мы получаем размытые сигналы и потерянный трафик. Эта проблема называется каннибализацией запросов, и грамотная кластеризация — основной инструмент её профилактики.
Дальше разберём, как группировать ключи по смыслу и пересечению поисковой выдачи, какие методы и сервисы выбрать, как от готовых кластеров перейти к посадочным страницам и каких ошибок стоит избегать. Без воды, с примерами из практики.
За восемь лет работы с проектами в e-commerce и услугах главный вывод по кластеризации простой: чем строже соблюдаем правило «один интент — одна страница», тем стабильнее растёт органика. Автоматика без ручной проверки не работает.

Булгун Ивикова
SEO-специалист
Что такое кластеризация запросов и зачем она нужна

Кластеризация запросов — это группировка поисковых фраз в логические кластеры по общему интенту пользователя и пересечению актуальной поисковой выдачи. Один собранный кластер соответствует одной посадочной странице. Базовая задача метода — превратить большое и неструктурированное семантическое ядро в чёткую карту, по которой строится архитектура сайта.
В SEO-практике этот процесс закрывает три фундаментальные задачи:
-
Структурная. Кластеры наглядно показывают, какие страницы вообще нужны ресурсу: какие категории создать в интернет-магазине, какие услуги выделить в отдельные разделы, какие темы отдать блогу.
-
Содержательная. В рамках одной группы запросы определяют, о чём писать на странице: какие подтемы раскрыть, какие смысловые модификаторы взять в заголовки H2 и тексты.
-
Защитная. Корректная группировка устраняет пересечение ключей между URL и защищает сайт от внутренней конкуренции.
Каннибализация возникает, когда поисковик видит на сайте две и более страниц, почти одинаково релевантных одному поисковому намерению. В этом случае алгоритмы Google и Яндекса сами выбирают каноническую страницу. И часто их выбор не совпадает с интересами бизнеса: вместо коммерческой категории с товарами в топ попадает статья из блога без корзины и кнопки покупки. Деньги мимо.
В проекте интернет-магазина детских товаров мы столкнулись с показательным случаем: запрос «купить детский манеж» поднимался то на категорийную страницу, то на статью-обзор «как выбрать манеж». Поисковик метался. После того как мы жёстко развели кластеры — коммерческий интент пустили на категорию, информационный отправили в блог, а сверху настроили внутреннюю перелинковку, — позиции по приоритетной коммерческой группе выросли с 18–25 места до 4–9 за три месяца.
Хотите понять, теряет ли ваш сайт трафик из-за каннибализации и слабой структуры семантики? Команда «Медиаконтекст» проводит точечный аудит ядра с разбором по кластерам — без шаблонных отчётов и обещаний «ТОП-1 за месяц». Закажите бесплатный SEO-аудит: покажем, какие группы запросов «съедают» друг друга и что с этим делать.
Как составляется кластер: принципы группировки ключевых слов
Любой рабочий кластер собирается на четырёх принципах: поисковый интент, пересечение SERP, учёт частотности и строгое разделение информационных и коммерческих ключей. Только их совокупность даёт результат, а не «папку с ключами».
-
Один интент — один кластер. Запрос отражает конкретную задачу пользователя. «Купить беговые кроссовки» и «беговые кроссовки цена» — один коммерческий интент. А вот «как выбрать беговые кроссовки» — уже другой, информационный. Смешать — значит лишить страницу шанса конвертировать читателя в покупателя, а лонгрид — шанса попасть в топ по «как выбрать».
-
Разделение типов интентов («процент коммерческости»). Коммерческие ключи с маркерами «купить», «цена», «заказать» идут строго на страницы услуг или витрины. Информационные («как», «что такое», «отзывы») — в блог или FAQ. На практике мы оцениваем долю коммерческой выдачи в топе: если коммерческость запроса выше 60%, он отправляется в магазин; если ниже 35% — в блог.
-
Пересечение поисковой выдачи. Если по двум запросам в топ-10 Яндекса или Google ранжируются одни и те же чужие сайты и URL, поисковик уже считает эти фразы близкими по смыслу. Это основной технический критерий для объединения ключей. Пересечение отдельных слов вторично — первична именно выдача.
-
Частотность запросов. Внутри сформированного кластера выделяют якорный высокочастотный (ВЧ) или среднечастотный (СЧ) запрос, вокруг которого наращиваются низкочастотные (НЧ). Это помогает назначить главенствующий фокус для метатегов Title и Description, а заодно для H1.
Алгоритм составления кластера — пошаговая логика:
Суть метода в том, чтобы не доверяться одной интуиции, а использовать фактическое поведение поисковых алгоритмов как объективный критерий. Если Google и Яндекс сегодня показывают по двум запросам одни и те же посадочные — машины уже признали эти интенты идентичными. Спорить бесполезно.
Методы кластеризации семантического ядра
Существует три основных подхода: ручная логическая группировка, автоматическая по топам SERP и машинная — на основе LLM и NLP-алгоритмов (через Python-библиотеки или low-code платформы вроде Loginom).
|
Метод
|
Принцип действия
|
Объём ядра
|
Точность
|
Затраты времени
|
|
Ручная
|
Логика и интент, без парсинга выдачи
|
до 300 запросов
|
Высокая (при опыте)
|
Высокие
|
|
Автоматическая (SERP)
|
По пересечению URL в топ-10
|
от 100 до десятков тысяч
|
Высокая
|
Низкие
|
|
Машинная (Python/ИИ)
|
По эмбеддингам и ML-моделям
|
от 1000 запросов
|
Средняя без дообучения
|
Средние
|
Для большинства стандартных проектов рабочий метод — автоматическая кластеризация по SERP с обязательной ручной валидацией. В современных AI-подходах запросы дополнительно проходят этап «нормализации языка», что улучшает машинное понимание. Но в классическом SEO именно SERP-метод остаётся золотым стандартом.
Ручная (логическая) кластеризация
Это распределение ключей вручную, силами специалиста, обычно в Excel или Google Sheets. Подходит для локального бизнеса, специфических микрониш и тематик, где автомату нельзя доверять ни одного решения.
Плюсы: полный контроль над логикой; независимость от временных «штормов» поисковиков; учёт нюансов ниши, которые алгоритм не считывает.
Минусы: процесс крайне медленный. Не масштабируется — ядро на 5000+ запросов вручную разобрать почти нереально без потери качества.
Для сайта стоматологической клиники мы делали ручную разбивку ядра на 180 фраз медицинских услуг. Тематика чувствительная: любая автоматическая ошибка привела бы к смешению информационных запросов о симптомах и коммерческих о записи к врачу. За пять месяцев доля их запросов в топ-10 выросла с 22% до 67%.
Автоматическая кластеризация по топам SERP
При автоматической разбивке сервис сам запрашивает топ-10 по каждому ключу и объединяет фразы в кластер, если у конкурентов фиксируется заданное количество общих URL.
Этапы скрытой работы сервиса:
- Робот снимает топ-10 (или топ-20) по каждому запросу.
- Анализирует попарно: сколько совпадений URL встречается между запросами.
- Если общих адресов больше выбранного порога — запросы склеиваются в группу.
Способ отлично работает в устоявшихся коммерческих тематиках, но даёт сбои в свежих хайповых нишах, где алгоритмы ещё сами не определились, какой контент показывать. В таких случаях помогает только ручная валидация.
Hard, soft и middle кластеризация: чем отличаются и что выбрать
Разделение на Hard, Soft и Middle зависит от требуемого порога пересечения URL. Это буквально настройка строгости инструмента — сколько общих сайтов в топ-10 нужно найти, чтобы программа решила объединить запросы.
-
Hard (жёсткая). Самый строгий подход. Требует, чтобы каждый запрос внутри кластера пересекался с каждым другим (например, 4–6 общих сайтов). Метод выдаёт максимально точные, но мелкие группы. Идеально для e-commerce: лучше сделать две точные страницы под микрокластеры, чем перегреть одну и получить риски по коммерческим факторам ранжирования.
-
Soft (мягкая). Запросы объединяются по цепочке от главного (маркерного) ключа. Если А пересекается с В, а В — с С, все трое падают в одну копилку, даже если А и С общих URL в выдаче не имеют. Подходит для крупных информационных статей и блогов, где текст раскрывает широкую тему.
-
Middle (умеренная). Рабочий и популярный компромисс (порог 3–4 сайта). Требует, чтобы каждый запрос пересекался с якорным, при этом часть ключей в группе связывается парно друг с другом.
Простой ориентир. Рабочий кластер — это не самый длинный список ключей, а список, который органично закрывает один интент пользователя на одной странице. Для проверки откройте выдачу: если по якорному запросу и по самому мелкому слову из вашего кластера ранжируются похожие магазины — группа собрана верно. Если разные типы сайтов — пора пересмотреть порог.
Сервисы и программы для кластеризации запросов
Инструментов много, и они делятся на десктопные программы, веб-сервисы и среды для работы с Big Data. Выбор зависит от бюджета и объёма семантики, не более того.
Прямая рекомендация аналитика. Если вы владелец малого бизнеса с небольшим интернет-магазином и без SEO-специалиста в штате — не лезьте сразу в Python и Loginom. Для ядра до 1000 запросов начните с бесплатных тарифов или недорогих лимитов в сервисах Кулаков Тулс или SeoRush. Этого функционала хватит для первых шагов и базовой структуры, и вы не потратите лишних бюджетов на инструменты, которые в вашей задаче избыточны.
Десктопные решения (Key Collector и аналоги)
Десктопные программы — Key Collector, Just-Magic, Rush Analytics — закрывают весь жизненный цикл семантики: от сбора подсказок из Вордстата до чистки и группировки по SERP. Это золотой стандарт для агентств: лицензия часто покупается один раз, а потоковая работа ограничена лишь лимитами антикапчи и мощностью ПК. Минус — процесс на тысячах запросов может идти часами из-за массового парсинга топов.
Онлайн-сервисы и веб-решения
Они удобны, когда нужно провести качественную группировку в браузере без установок и настройки прокси.
-
Кулаков Кластеризатор — старейший и понятный инструмент. Кластеризует по SERP, имеет гибкие настройки порогов, выгрузку в Excel и адекватные цены.
-
SeoRush / Topvisor — комплексные гиганты рынка. Умеют не только объединять слова, но и тут же отправлять их в модуль проверки позиций для мониторинга индексации и динамики кластеров во времени.
Аналитические low-code платформы (Loginom) и Python-библиотеки (BERTopic) хороши для интеграции во внутренние ERP-системы крупных брендов. Но в классическом SEO они часто проигрывают: объединяют фразы по текстовому сходству смыслов (эмбеддингам), а не по реальной коммерческой выдаче поисковиков. А продают всё-таки в выдаче, а не в эмбеддингах.
Если хочется не разбираться в десятке сервисов, а сразу получить готовую кластеризованную семантику и план её внедрения в структуру сайта — мы делаем это в рамках продвижения сайтов через SEO . Подходит и для интернет-магазинов, и для корпоративных сайтов: стоимость SEO-продвижения рассчитываем после короткого аудита, без шаблонных пакетов.
Пошаговая кластеризация семантического ядра: пример
Процесс жёстко разбит на 7 этапов. Пропустите чистку от мусора — кластеризатор выдаст неверные связи и потянет за собой ошибки в структуре.
-
Сбор семантики. Базовая выгрузка подсказок Яндекса, Google и конкурентов. Формирование сырого, объёмного перечня фраз.
-
Расширение (нормализация). Добавление синонимов, жаргона, аббревиатур. В ML-подходах запросы переводятся в базовые сущности (нормализуются), чтобы алгоритм не путал «iphone» и «айфон».
-
Чистка и анализ частотности. Удаление нулевых запросов (точную частотность снимаем через оператор «!») и нецелевых формулировок.
-
Выбор метода (порога). Для интернет-магазина — Middle (3–4 пересечения). Для инфопортала — Soft (2–3).
-
Запуск. Система парсит SERP и формирует первичные таблицы кластеров.
-
Ручная доработка. Эксперт разбивает крупные кластеры на два, если внутри оказались слова из серии «настройка» и «заказать услугу».
-
Финальная оценка качества. Сверка с поисковой выдачей по якорным и хвостовым запросам, проверка на пересечение с действующей структурой сайта.
Пример из ниши «беговые кроссовки». Загрузили 1400 запросов. Использовали Middle (порог 3). Получили коммерческий кластер:
-
купить беговые кроссовки (якорный ключ, частота 15 200)
-
беговые кроссовки цена (3 400)
-
беговые кроссовки заказать (1 800)
Эти конкурентные ключи мы отправили на страницу категории обуви. Информационные запросы — «как выбрать обувь для бега», «лучшие модели 2026» — система вынесла в смежный, но отдельный кластер, и под них мы создали статью в блог. Никакого пересечения, никакой каннибализации.
Как распределить ключевые слова по страницам сайта
Базовое правило, которое нужно зашить в голову перед любым проектом: один кластер — это строго одна посадочная страница. Разные кластеры — разные URL. Без исключений.
Логика привязки выглядит так:
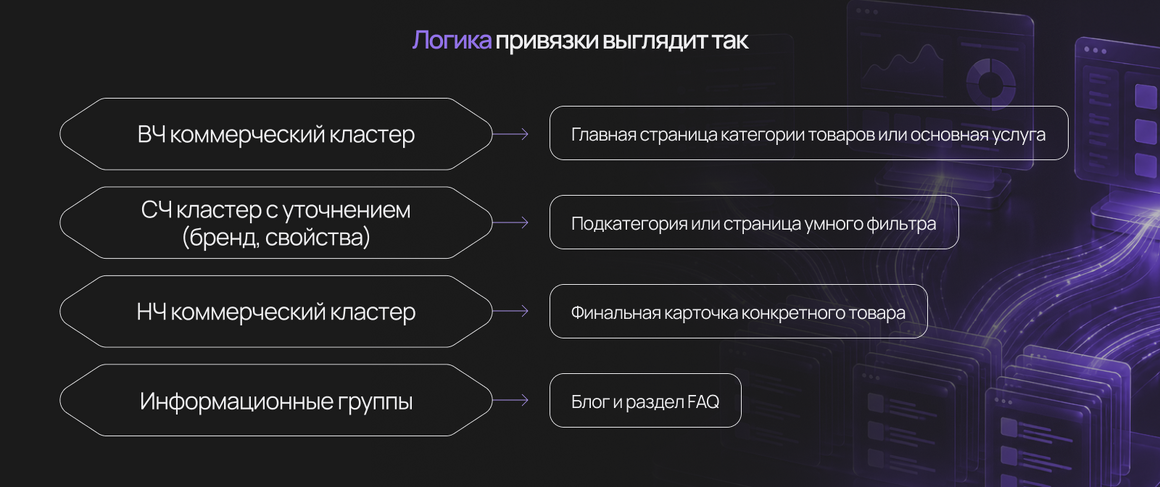
Отдельно держим в голове оптимизацию метатегов и заголовков. Title получает якорный запрос. А вот с H2 интереснее. В эпоху AI-поиска каждый внутренний подзаголовок H2 должен быть относительно автономным и сразу давать пользователю прямой смысловой ответ на подвопрос. Это рекомендация уже не теоретическая — она работает в задачах GEO-продвижения под нейросетевые ответы, где ИИ собирает выдержки из текста и формирует свой саммари.
Важно понимать, когда нужна новая страница, а когда — нет. Если внутри готового кластера появилась подгруппа из 5–8 ключей с другим уточнением (например, «бренд + модель»), это сигнал к созданию подкатегории или фильтра. Если же отличий по интенту нет, а ключи просто синонимичны, — это всё ещё одна страница.
В проекте по услугам ремонта мы однажды обнаружили каннибализацию по 23 жирным фразам: трафик разрывался между старым лендингом и новой версией страницы. Как только мы объединили интенты в один URL и настроили 301-редирект со второго, органический трафик по этим позициям вырос на 41% за два месяца. Никакой магии — только дисциплина в распределении кластеров.
Типичные ошибки при кластеризации и как их избежать
Самые опасные ошибки всплывают не в момент работы с программой, а спустя полгода — когда сайт не движется в топе из-за смешения запросов. К этому моменту уже жалко переделанной структуры и потраченного времени.
-
Неправильный выбор порога схожести. Слишком высокий (hard) на информационном ядре породит хаос пустых страниц; слишком низкий (soft) в магазине склеит ключи «купить» и «обзор», убив всю конверсию. Решение: тестируйте порог сначала на случайной выборке в 100 запросов и сверяйтесь с результатами SEO-аудита.
-
Слепое доверие автоматике без ручной проверки. Автоматические сервисы регулярно склеивают многозначные редкие ключи. Если специалист не пробежится по таблице глазами — на сайте появится мусор, который потом придётся вычищать вручную.
-
Игнорирование интента на старте. Забыли вручную разделить коммерческие и информационные запросы? Кластеризатор (особенно с мягкими настройками) переплетёт их, опираясь на случайную турбулентность поисковой выдачи. Маркируйте слова до загрузки в инструмент.
-
Отсутствие оценки качества. Готовые группы нужно проверять — по контрольным запросам, по сверке с выдачей и по логике бизнеса. Сборка ради сборки не работает.
Описанные подходы к чистке и выбору порогов опираются на тысячечасовую агентскую практику и общую логику работы краулеров. Индустриальных ГОСТов здесь не существует, но базовые принципы качества исследований можно заимствовать из научной среды.
Ответы на частые вопросы о кластеризации запросов
Могу ли я сделать кластеризацию сам, без специалиста?
Да. Если у вас сайт на 50–100 страниц или узкая ниша, базовую группировку можно выполнить в любом онлайн-сервисе (SeoRush, Topvisor) или даже руками в таблице. Главное — не смешивайте продающие страницы и образовательные статьи.
Что значит «кластеризовать» в SEO?
Сгруппировать список поисковых фраз в «коробки» (кластеры) на базе выдачи и смысла. Каждая такая коробка становится одной страницей вашего сайта.
Чем кластеризация запросов отличается от кластеризации текстов?
Группировка больших текстов — это задача NLP-нейросетей (определение смысловой близости абзацев). SEO-кластеризация работает не с длинным текстом, а с короткими фразами, и ключевым критерием совпадения выступает поведение Яндекса и Google — одинаковые ли сайты находятся в топе по этим фразам.
Можно ли обойтись только бесплатными тарифами сервисов?
Для сайта-визитки с парой сотен фраз — абсолютно да. Если у вас классический интернет-магазин с десятками категорий, лимитов не хватит, а экономия пары тысяч рублей на подписке выльется в грубые ошибки SEO-проектирования.
Нужно ли переделывать ядро через год?
Пересобирать всё с нуля не нужно, если бизнес не изменился. Но выдача поисковиков не статична. Раз в год-полтора имеет смысл выборочно обновлять кластеры в главных, самых доходных категориях — поисковый интент у части пользователей со временем эволюционирует.
Сколько ключей реально кластеризовать за один заход?
В онлайн-сервисах на тарифах среднего уровня — от 1 000 до 10 000 запросов за процедуру. В Key Collector и Python-решениях ограничений по объёму почти нет, упор идёт в скорость снятия SERP и лимиты антикапчи.
Итог прост. Кластеризация — не разовая техническая операция, а основа всей структуры сайта. Делать её надо аккуратно, с пониманием интента и обязательной ручной проверкой. Один кластер — одна страница. Это правило сэкономит вам бюджет и месяцы переделок.











